
New Agentic QA Features in Playwright
A feature packed Playwright 1.59.0 was released last week. One of my new favorite features is the new flag that can be used when running your playwright tests --debug=cli. This is lower level infrastructure that allows you to
# Installs latest playwright-cli
npm install -g @playwright/cli@latest
# Installs the latest skill (run inside a repo you want to use the skill in)
playwright-cli install --skillsWhen you have a test that is failing you can run a prompt within Claude Code (or any coding harness that supports skills)
/playwright-cli debug my playwright testThis will run the debug section of the /playwright-cli command utilizing the --debug=cli and debug your test. The output I got from my experiment was a few options, for me to choose from.
- App bug — the element should stay disabled when "No" is selected, but the app is incorrectly enabling it.
- Test needs updating — the business logic changed and the element should now be enabled when "No" is selected. Change line 597 from toBeDisabled() to toBeEnabled().
Do you know whether this is a test fix or an app bug?
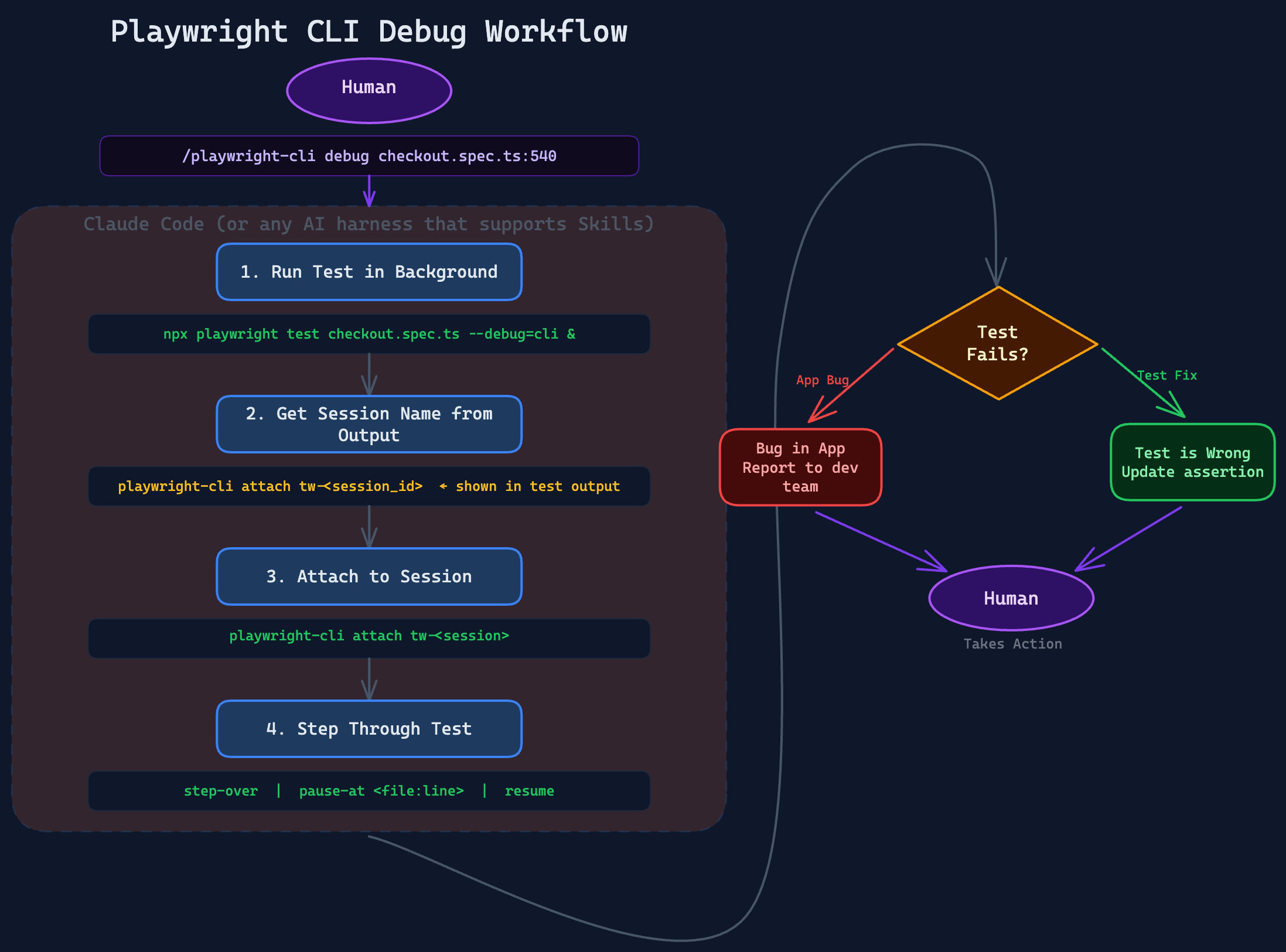
The tooling and skill is providing me "the human!" a time to inspect and provide feedback before moving forward. As Rahul Parwal puts it in his article below "Agentic QA = Agentic Execution × Human Judgment" this is here today with these tools.
Headlines & Launches
The Witness Stand: Applying Classical Testing Thinking to AI Agent Outputs
via The Quality Forge (Dragan Spiridonov)
A quality tool reported 95% coverage on a file with zero tests. Dragan Spiridonov's diagnosis: teams have built hope architectures, not trust architectures. Classical testing vocabulary - oracles, checking vs. testing, testability - maps onto agentic systems with uncomfortable precision. The question that exposed the problem was the one testers have always asked: where is the evidence?
AI Is Vindicating the Role of the Software Tester
via arcigo.blogspot.com (Armando Cifuentes González)
AI is turning everyone into software testers - developers now spend most of their time analyzing whether AI did what they asked, correcting and adjusting. Two lines worth repeating: "Automation is not the same as testing" and "We must be more critical of what AI generates for us and not blindly trust it." The skills testers have always had are now the skills everyone needs.
What Is Agentic QA? AI Agents + Human Expertise in Testing
via MuukTest Blog (Rahul Parwal)
A clear framework: Agentic Execution x Human Judgment - zero value if either side is missing. AI agents handle execution, coverage, and regression at scale; humans retain decision authority on intent, risk, and release trade-offs. Part 3 of a 4-part series on QA at the speed of AI-driven development.

Falling behind on test automation and AI adoption? DevClarity's QA Practice gets your team up to speed fast - with hands-on training, proven workflows, and measurable results within 30 days.
Tools & Frameworks
Multi-Agent Test Suite Generator: 6 AI Agents, One URL, Complete Test Suite
via LinkedIn (Hikmet Demir)
A 6-agent LangGraph/LangChain system that takes a URL and produces a complete test suite - locators, test cases, Cucumber feature files and step definitions. Includes a self-healing agent that fixes broken locators automatically. Open source on GitHub.
QA Agent Hub: Specialized Prompt-Driven QA Agents for GitHub Copilot
via LinkedIn / GitHub (Bruno Peres Christino / Betsson Group)
A reusable hub of specialized QA agents for GitHub Copilot in VS Code - covering bug reporting, test planning, coverage analysis, release readiness, root-cause triage, and automation gap analysis. The Write Tests agent can write or update automated tests directly in the codebase when framework context is available. Open source.
Build an AI QA Agent for Expo Apps with EAS Workflows in Minutes
via Expo Blog (Michal Pierzchala / Callstack)
A practical mobile QA agent setup using EAS Workflows and agent-device: for every PR, reuse existing builds, boot an emulator, let an agent inspect the UI and take screenshots, post a QA summary back to the PR. No giant test framework - just a working baseline you can stand up in minutes, from the creator of React Native Testing Library.
qa-ai-testpilot: Plain-Language QA Agent Using Playwright and Claude API
via LinkedIn (Mohamed Khattab / Celonis)
Describe what to test in plain language - the agent converts it to executable steps using Claude for dynamic planning, runs real browser actions via Playwright, captures screenshots, and generates both manual test cases and automation drafts from the same input. Native Jira/Xray/Zephyr support. Open source.
Techniques & Tutorials
Testing LLM Outputs: A Hands-On Guide to DeepEval Metrics
via LinkedIn Pulse (Serhii Smetanskyi)
A practical walkthrough of 30 DeepEval metrics for testing LLM outputs - covering RAG (answer relevancy, faithfulness, contextual precision/recall), safety, agents, and chatbots. Built on pytest so it drops straight into existing CI pipelines. Includes a GitHub repo with both positive and negative test cases for each metric.
AI-Powered Cypress Failure Orchestrator: Real Bug or Flaky Test?
via LinkedIn (Cypress Ambassador / Saran Kumar)
A 3-agent pipeline that classifies Cypress CI failures automatically: Planner groups errors, Analyzer sends failure data to GPT-4 for root-cause classification (production bug, broken selector, data issue, or flaky test) with a confidence score, Decision agent maps the result to a pipeline action based on your safety policy. Critical bug in checkout? Blocked. Low-confidence flaky test? Allowed with a warning. Generates PR comments and integrates with GitHub Actions and Jenkins.
AI Supported Testing Experiments
via GitHub (Alan Richardson / EvilTester)
Alan Richardson is documenting time-bound, repeatable AI testing experiments covering browser automation, counterstrings, MCP tooling, and self-directed learning. Each experiment is designed to be re-run over time to track how AI testing capabilities evolve. Includes an interactive learning interface and experiments with both cloud and local models.

If you’re working with Playwright, test automation, or exploring how AI fits into your workflow, this should be worth your time. You can also grab your seat with an exclusive 40% early bird discount using code: BUTCH40
Research & Data
AI and Testing: LangChain Templates (Part 4 of series)
via Tester Stories (Jeff Nyman)
Part 4 of Jeff Nyman's AI and Testing series: LangChain Templates as a way to standardize and reuse prompts across testing workflows. Builds on the local LLM and LangChain foundations from Parts 2 and 3.
Quick Links
GuruQA: AI-Powered API Testing Platform (Free Beta) (guruqa.com) - paste your OpenAPI spec, get a full AI-analyzed test report in seconds; built by a 10-year QA lead
Roadie: Hardware KVM with WebDriver BiDi so AI Agents Can Set Up Physical Devices (LinkedIn / Jason Huggins) - $86 in parts, works before SSH exists, agents setting up agents
WebdriverIO MCP: Attach a Live Chrome Session to Your AI Assistant (LinkedIn / Vince Graics) - set up your state, hand the browser to the agent; device emulation included
Agentic QE v3.9.0: Context Compaction, Background Daemon, Plugin System (LinkedIn / Dragan Spiridonov) - production hardening release; upgrade with npx [email protected] init --auto
How Do You Use Claude Code as a Manual Tester? (r/QualityAssurance) - practitioners sharing what's actually working
Speed Up Claude Code: Pre-Approve Tool Permissions in .claude/settings.json (LinkedIn / Nikolay Advolodkin) - stop the permission prompts, keep dev moving
If something in this issue made you think differently about how your team approaches AI in testing, pass it along. The best conversations about AI and QA are happening in Slack channels and stand-ups, not just newsletters.
Have something worth featuring? Reply and send it my way, I read every link.
Thanks for reading,
Butch Mayhew